Google hasn’t yet provided any direction on Android as a tablet platform, which means that the Tab is held back by lagging application support and software that doesn’t fully take advantage of the extra screen real estate.
— Part of the conclusion of Engadget’s Samsung Galaxy Tab review. This is going to plague every Android tablet until Google takes a clear, bold stance by making their own tablet versions of Android’s built-in apps — which may never happen.
There’s likely to be a big chicken-and-egg problem: Google probably won’t care to devote any resources to good tablet interfaces for Android software unless one of the hardware tablets takes off, but none of the tablets are likely to take off with half-assed tablet interfaces on its software. It sounds like today’s Galaxy Tab is the Android equivalent of “just a big iPod Touch”, and it’s up to Google — not Samsung — to make it more meaningful.
This is the kind of problem that Apple simply doesn’t face in their products: by keeping it all under the same roof and having a ruthless dictator with high standards and great taste at the top, they would never release hardware that begs for software. They’d just hold the hardware back until the software was ready — and not just running, but thoughtfully tailored for the device.
Watts Martin’s analysis of the migration toward “app console” hardware:
The model we’re moving toward, though, is premised on the idea that computers shouldn’t require routine tech support. Again, look back at game consoles: an Xbox 360 or Playstation 3 is a fully programmable computer with networking capability, offline storage, removable media, the whole shebang, yet all of that is invisible to the user. What file system does a Playstation use and what directories does it put your downloaded games in? The correct answer is: “Who gives a shit?”
And if what you do with a computer is spreadsheets and flow charts and word processing documents and slide presentations, web browsing and media watching and game playing, even recording music and editing photographs and writing text adventures, there’s an excellent case to be made that you should not have to give a shit about any of that, either. But right now—no matter what platform you’re using—you kinda do.
Not only do I think he’s correct, but this is a great migration for the industry.
Think of how many people are so afraid of their PCs that they only do the bare minimum with them and never venture into unknown territory because they’re afraid of “breaking” their computers. How many of them recently bought iPads and have become much more confident and adventurous with usage and applications, since Apple tricked them into thinking that the iPad isn’t a computer?
A common fallacy is assuming that any new platform in an exciting market — recently, smartphones and tablet computers — will be flooded with developers as soon as it’s released, as if developers are just waiting outside the gates, hungrily waiting to storm in.
In two recent cases, that’s exactly what happened: the iPhone and the iPad. (And probably the Mac App Store next.) So important people, including the tech press, consumers, and many hardware manufacturers themselves, assume that every new hardware platform will be greeted with the same rush of high-quality software.
Steve Jobs knows this is wrong, even though his company is the beneficiary of the best cases of the supposed effect. As he said, in the recent earnings call:
You’re looking at it wrong. You’re looking at it as a hardware person in a fragmented world. You’re looking at it as a hardware manufacturer that doesn’t really know much about software, who doesn’t think about an integrated product but assumes the software will somehow take care of itself. And you’re sitting around saying, well, how can we make this cheaper? Well, we can put a smaller screen on it, and a slower processor, and less memory, and you assume that the software will somehow just come alive on this product that you’re dreaming up, but it won’t. … Most [developers] will not follow you.
The problem is that hardware manufacturers and tech journalists assume that the hardware just needs to exist, and developers will flock to it because it’s possible to write software for it. But that’s not why we’re making iPhone and iPad software, yet those are the basis for the theory.
We’re making iPhone software primarily for three reasons:
Dogfooding: We use iPhones ourselves.
Installed base: A ton of other people already have iPhones.
Profitability: There’s potentially a lot of money in iPhone apps.
Of course, the last two are related: it’s hard to have one without the other, but subtle implementation or demographic differences can make a huge installed base yield relatively low profitability.1
Without dogfooding, we aren’t motivated to make our software with craftsmanship and pride.
Without an installed base, too few people will be able to buy our software for it to be worth generalizing and releasing.
Without profitability, we can’t afford to make and support it.
For most platforms, all three conditions need to be met for a significant number of developers to justify writing software for them.2
This worked so well for the iPhone because we already had iPhones for a year before we could make apps for them. Thousands of developers already owned and loved their iPhones: they were so good that we all bought them without having any apps at all. And on day one of the App Store, there were already 6 million iPhones in the world. (Three days later, there were 7 million.) And the app-buying process couldn’t be easier: it was, and remains, the easiest purchasing process in the entire software industry. Dogfooding, installed base, and profitability were all very strong.
The iPad was trickier: it started with an installed base of zero. But the product was so good and so compelling that we all knew that it would sell like crazy from day one. And it was so good that we all got iPads, too, solving the dogfooding issue. And since it retained the same easy purchasing process as the iPhone App Store, and we knew it would have a big installed base shortly, the profitability was promising as well. So a bunch of us made great iPad apps.
Now, consider this fall’s tablet computers. Can you say with confidence that any of them will address these three needs well enough, and for enough developers, to ensure a steady supply of quality software?
I can’t.
For instance, both BlackBerry and Android have huge installed bases, but their marketplaces and payment procedures significantly reduce the profitability of maintaining good apps on their platforms. ↩︎
At least one condition being extremely powerful can justify shortcomings in the others. For instance, a lot of developers who don’t particularly care for Windows make Windows software anyway because of its huge installed base. And some developers make software for far less popular devices because they own them and want the software for themselves (like my Kindle support) despite the low likely profitability. But for the most part, a platform needs all three conditions to be strong. ↩︎
In general, iPad styluses follow an incorrect cognitive mapping. The vast majority of them are designed to look and feel like a pen. Why? Writing or drawing on the iPad feels nothing like using a pen or pencil. For one, the fidelity is way too low. For one, the fidelity is way too low. Also, it is pretty awkward to rest your palm on the screen of the device because it throws off the capacitive detection. Writing on an iPad, to me, feels like writing on a dry erase board. Fast, simple, low fidelity. The perfect iPad stylus is one that feels like a dry erase marker.
I’ve never used an iPad stylus that didn’t feel weird. I couldn’t articulate why, except to say that the tips all felt too wide and squishy. But Dan Provost nails it here: it really behaves more like a whiteboard for writing or quick sketching, and any stylus and corresponding software should be designed as such.
Commercialize the dry-erase-like stylus, and I bet a lot of people will buy them. I sure would.
iOS apps display a prerendered, static image when they launch called Default.png. Developers can set it to anything they like. This is Instapaper’s:
This matches the iOS convention of showing the app’s typical interface, but empty, so it looks like it has fully loaded (before it actually has) and then the data “pops” in a second or two later. It’s a trick that the original iPhone employed to make the app launches seem faster and more responsive. The pictured interface is just a decoy: it’s a static image file that doesn’t necessarily have any relation to what the interface will actually look like when it loads.
Apple’s apps have always had an advantage with this approach: they can change their launch images at runtime. Before quitting, they can render an image of how they actually look, so when they launch next and restore their state, it looks seamless.
But third-party apps can’t change theirs dynamically. This poses a visual continuity problem: we need to show the same launch image even if the app is restoring a state that doesn’t look anything like it.
In Instapaper’s case, this is a problem in two major states that it may launch in:
The reading view, which looks nothing like the article-list view.
Dark mode.
Dark mode is the much bigger problem. In a dark room, it’s jarring and blinding for the bright-white launch image to blink briefly when launching the app into dark mode. I’ve gone to ridiculous lengths in the past to avoid showing white screens or flashes while in dark mode, so this one major exception irritates me.
One way to avoid this issue is to make the launch image dark instead of light. I can’t just make it a picture of the dark-mode interface, because then the (much more common) light-mode interface would look strange when it appeared after the dark launch image.
Another option, fairly popular among developers, is to make a splash screen. I considered this for 2.3, but chickened out. Here’s a quick mockup of what I had in mind:
(That’s the dark-mode background color, #141414.)
This has its own set of problems:
It’s jarring to users because none of Apple’s apps do this.
If it blinks by too quickly, like it will on most new, fast iPhones and the iPad, the user hasn’t had time to recognize it and feels like they just missed something.
Maybe it’s just me, but I think splash screens look cheap and outdated.
So both launch-image types have significant downsides. It’s a bit like the Settings-go-in-the-Settings-app dilemma, but I think that one has been definitively settled by now (in most cases, they don’t).
In this case, I don’t think either option is good enough. I’m sticking with the Apple convention1 for now, but it’s always going to annoy me until I come up with a better solution.
Rule #1 for non-game iPhone apps: If in doubt, do it Apple’s way. ↩︎
This is my new audio podcast with Dan Benjamin on his excellent 5by5 network. It’s about development for Apple platforms and the mobile web, generally, with news and discussion related to that world. In addition to the podcast feed, it’s also broadcast live here every Thursday around noon (follow me on Twitter to see when we start each week).
The size of a Starbucks store is directly proportional to how much of a pain in the ass it will be during rush hour. Put another way, the bigger a Starbucks is, the more you’re going to want to stab yourself in the eyeballs before you get your “coffee”.
Normally I wouldn’t link to something about Starbucks, but since he put “coffee” in quotes, I think he’s admitting that what’s served there is simply an approximation of the branding of the image of coffee-inspired beverage products.
Got this great story from Give Me Something To Read, Instapaper’s companion site edited by Nostrich. I wanted to quote nearly every paragraph.
What’s great about this article is that it provides an intelligent counterpoint and reality check against all of the usual “the entire U.S. food system sucks and is killing our children but first making them fat” narrative of the documentaries and investigative-entertainment shows that we all enjoy watching.
The school administrators responsible for their food programs largely aren’t being ignorant, cheap, or irresponsible: they’re usually doing the best they can in the bureaucratic, societal mess they’re stuck in.
One of the big issues is that many kids won’t eat the school lunches if they’re not appealing, and nearly every alternative they’re likely to choose is less healthy. But if you give them too many appealing choices, they’ll just eat french fries and ice cream and ignore the healthier dishes. This West Virginia policy is genius:
Goff adds there are no outside vendors and “we do not permit a la carte sales.”
Author Jan Poppendieck explains that a la carte food “undermines the nutritional integrity of school meals.” She says kids “can pick at the parts of school lunch they feel like eating and then fill up with pastries. They have on their tray a meal that has been planned to meet nutrition standards, but then they can buy candy, and research shows that they do. Children who were in school without a la carte options ate more of the official lunch.”
Removing choice is often beneficial for everyone if those making the choice are likely to choose against their best interests.
And nearly every enforced regulation, while good-natured, may cause unintended workarounds:
School meals must meet two sets of standards to be reimbursable. One, they must provide a minimum amount of proteins, minerals, vitamins and calories. Two, meals must contain a maximum of 30 percent of calories from fat and 10 percent from saturated fat. […]
If a school district finds a meal has too much fat, it can raise the calorie count to lower the proportion of fat. “The quickest, least expensive fix … is to add sugar,” writes Poppendieck. “Sweetened, flavored milks have become a staple of the cafeteria, and desserts are making a comeback. An additional serving of vegetables, the element in which American diets are most glaringly deficient, would usually fill the calorie gap, but it is beyond the financial reach of most schools.”
Like The Wire, this article helps illustrate that the causes of what we see as an isolated issue — unhealthy cafeteria food — are actually broad, systemic failures, side effects, and incentives gone wrong with no simple fixes.
The company will also announce that it has raised $800,000 in venture capital, the first step in moving along the path from building an app to running a profitable business.
I’m happy for the Pulse team. Pulse is great. But this quote, for which the blame lies more on this article’s author, is (probably unintentionally) ridiculous.
Hundreds (if not thousands) of iPhone and iPad apps are made by profitable businesses that didn’t raise any venture capital. In fact, making the app free is going to remove its biggest revenue stream, which is likely to be generating at least $25,000 per month.
I’m sure they went into this responsibly and have a good chance of making more later in other ways, as the article mentions. But in the short term, this move is likely to make them quite unprofitable. That’s why businesses raise venture capital: to cover their costs when they’re unprofitable so they can grow into something that’s hopefully larger and very profitable later.
It’s ridiculous, incorrect, and insulting to those (like me) who have chosen the traditional business model — charge money, spend less than you make — for this author suggest that giving away your product for free and paying your expenses with VC money is the “first step” to make your app development “a profitable business”.
I mentioned earlier on Twitter that my home computer downloaded a 22 GB database dump every three days as part of Instapaper’s backup method, and a lot of people expressed interest in knowing the full setup.
The code and database are backed up separately. The code is part of my regular document backup which uses a combination of Time Machine, SuperDuper, burned optical discs, and Backblaze.
The database backup is based significantly on MySQL replication. For those who aren’t familiar, it works roughly like this:
The “master” database is configured to write a binary log (“binlog”) of every change it makes to the data.
A snapshot of the entire database is taken, noting the current position in the binlog, and copied to the “slave” server.
The slave server can then start itself up with that snapshot, knowing what binlog position it needs to start from, and continuously stream the binlog data from the master, replicating every change that the master makes, to keep itself up to date.
And the binlogs can be decoded, edited, or replayed against the database however you like. This is incredibly powerful: given a snapshot and every binlog file since it was taken, you can recreate the database as it was at any point in time, or after any query, between the time it was taken and the time your binlogs end.
Suppose your last backup was at binlog position 259. Someone accidentally issued a destructive command, like an unintentional DELETE or UPDATE without a WHERE clause on a big table, at binlog position 1000. The database is now at position 1200 (and you don’t want to lose the changes since the bad query). You can:
Instantiate the backup (at its binlog position 259)
Replay the binlog from position 260 through 999
Replay the binlog from position 1001 through 1200
And you’ll have a copy of the complete database if that destructive query had never happened.
Replication is particularly useful for backups, because you can just stop MySQL on a slave, copy its data directory somewhere, and start MySQL again. The directory is then a perfect snapshot with binlog information (in the master.info file). If you can’t afford the slave’s downtime, or you want to snapshot a running master without locking writes, you can use mysqldump if the database is small or xtrabackup if it’s big, but it’s really best to dedicate a slave to backups if you can.
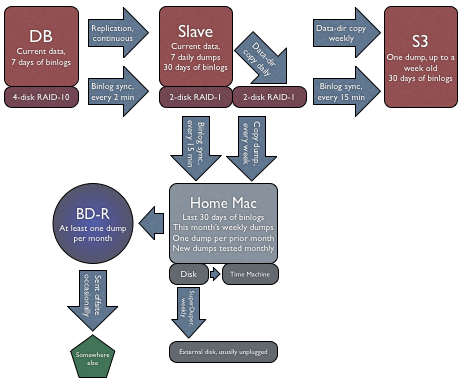
So here’s how I use replication for Instapaper’s backups: (click for larger version)
UPDATED, one day later:Inspired by the emails I’ve gotten in response, I’ve accelerated my S3 plans and did it all today. Now featuring automatic S3 backups as well. I’ve updated the diagram and description to include this.
The slave takes snapshots (“dumps”) of its data directory every day and continuously copies the binlogs from the master to its own disks and to my home computer with rsync. Once a week, it copies that day’s entire data dump to Amazon S3 and my home computer.
The dumps have the binlog name and position conveniently in their filenames:
These are additionally backed up from my home computer with Time Machine and SuperDuper. Additionally, I occasionally burn a Blu-ray disc with the most recent dump, and I take some of them offsite.
The slave is usually within 1 second of being up to date. And since the binlogs are synced every few minutes, the copies on my home computer and S3 are almost always within 15 minutes of being current.
Room for improvement
Of course, there’s always room for improvement in a backup scheme:
If I store more binlogs, I could get away with less-frequent dumps sent to my home computer. (As the data size grows, I’ll need to do this.)
My offsite transfers should be more frequent.
The backups should be tested automatically, in addition to the monthly manual testing that I perform now.
And you can probably think of an improvement that I haven’t considered. If so, please email me. Thanks.
If you wanted your iPhone or iPad app to work with older versions of the OS, or if you wanted to make a universal app that ran on both iPhone and iPad, you need to ensure that the code never tries to call a method or instantiate an object that doesn’t exist on its OS.
For example, the iPhone doesn’t support UIPopoverController, and iOS 4.1 doesn’t support 4.2’s new printing API, so I need to ensure that my universal app never attempts to show a popover on iPhone, and never attempts to print a document on pre-4.2 OSes. If I try to access functionality that doesn’t exist, the app will crash.
The nature of Objective-C requires the linker and runtime to know about any declared types in the app, so even if I have a pointer to an unsupported object, it will crash on launch. The solution before OS 4.2 was to generically type any references with id and use NSClassFromString() to call methods:
if (UI_USER_INTERFACE_IDIOM() == UIUserInterfaceIdiomPad) {
// dyld errors on iPhones crash the app on launch
UIPopoverController *p = [[UIPopoverController alloc] init...];
// dyld won't crash on launch
id p = [[NSClassFromString(@"UIPopoverController") alloc] init...];
}
Unfortunately, there are some conditions where that couldn’t work, such as if you wanted to have a subclass of a new class in your app. I ran into this issue when making Instapaper 2.3.1’s Print feature, which needed a custom subclass of UIPrintPageRenderer for a feature I wanted. If your app contains a subclass of an unsupported class, even if it’s not instantiated, it will crash on launch. You can make a subclass dynamically, which is like the subclass equivalent of using id and NSClassFromString(), but it’s difficult and messy.
The other option to avoid all of that is weak-linking, which makes the runtime manually look up the existence of every symbol before its first use. Weak-linking allows direct subclassing from new classes and doesn’t require the id pointers and NSClassFromString(). But it can dramatically slow performance if a lot of symbols are weak-linked.
Prior to the iOS 4.2 SDK, you could only mark entire frameworks for weak-linking, which usually meant all of UIKit (and potentially Foundation and libSystem, depending on what you needed). This could cause potentially fatal slowdowns on launch, especially on older hardware, which made this a poor option for many apps.
The iOS 4.2 SDK added a significant improvement: automatic weak-linking of only classes that required it, instead of entire frameworks. (As far as I can tell, it’s an automatic and officially supported version of this workaround.) But it only enables this support under certain conditions:
Your project’s Base SDK must be iOS 4.2 (or greater in the future).
Your project’s Deployment Target must be iOS 3.1 or greater. (So you need to give up pre-3.1 iPhone compatibility.)
Your project’s C/C++ Compiler Version must be LLVM GCC 4.2 (if you need support for pre-4.0 iOS) or LLVM compiler 1.6 (if you only support iOS 4.0 and above, because it won’t weak-link support for blocks1).
If you build under these conditions, you can safely subclass or have pointers to whatever you want (as long as you’re careful not to instantiate them when they’re not available), and you can check for a class’ availability at runtime like this:
if ([UIPopoverController class] != nil) {
// UIPopoverController is available, use it
UIPopoverController *p = [[UIPopoverController alloc] init...];
}
And your app can be compatible with all iPads, and all iPhones and iPods Touch back to version 3.1.
This is actually a bug that’s fixed for the upcoming LLVM compiler 1.7. ↩︎
This was my first full year at the helm of Give Me Something To Read, and to mark it, I’ve compiled this list of the best articles and essays I posted through 2010 (limited to those that were actually published in 2010).
This is a great collection of interesting content to load up into Instapaper for your Thanksgiving travels. To make it easier to add them to Instapaper, there’s a handy Read Later button next to each one.
What are you waiting for? Go add some great material to your reading list!2
He’s not dying or getting fired or anything. This is just a summary of his 2010 work. ↩︎
Astute readers may note that I claim to conserve exclamation points. This doesn’t mean that I never use them — they’re just reserved for special occasions in order to retain their significance. ↩︎
Some people buy too many shoes or collectible figurines. I buy headphones.
I currently have four pairs: two full-sized pairs for home and office use, and two portable pairs for riding the train and walking.
From left to right:
Beyerdynamic DT-880, very “open” headphones which let a lot of sound in and out, sound amazing, and are very comfortable. But their sound is so audible (and annoying) to others nearby that I can only recommend them for situations in which no other people will be in the same room. (previously)
Sennheiser HD 280 Pro, closed headphones that I would choose without hesitation if I could only own one pair of headphones and needed them mostly at home or work (especially work). (previously)
Bowers & Wilkins (B&W) P5, portable “luxury” headphones, and the only ones I own with the iPhone-compatible volume-clicker/microphone thing in the cable. (It’s identical to the Apple clicker, but black. Must’ve licensed it from Apple.) UPDATE:Found a fatal flaw.
Sennheiser PX 200-II, my lightest and smallest set and the only reasonably foldable ones, but they don’t sound particularly great and have a fatally annoying volume-knob module in the middle of the cable, and its clothing clip has already broken off. (previously)
I just got the B&W P5 at Apple’s Black Friday sale (for $72 off) to replace the PX 200-II, but when we were in a very quiet room later that night, Tiff could hear my music a bit too clearly from a few feet away.
I was worried that my music may be annoyingly audible to nearby train passengers — after all, one reason to buy closed headphones is to avoid that — and I really don’t want to be That Guy.
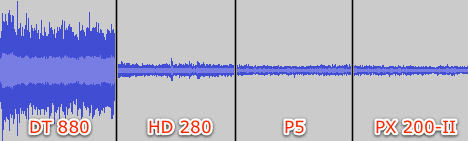
So when I got home, I devised a test to compare all of my headphones and see if the P5 leaked too much sound for social comfort. But I don’t have an SPL meter, so I improvised:1
Obviously, the open DT 880 leaks far more sound than the closed models, which wasn’t a surprise.
The other results are pretty good news for the P5: surprisingly, the big 280 Pro that I thought was completely sealed from the outside world leaked just as much sound as the P5 and the PX 200-II, which isn’t much but is audible in very quiet rooms or at very close range.
And none of the closed headphones were as quiet at close range as I thought. Sorry for all of the Phish, Topherchris.
This wasn’t 100% scientific: in addition to whatever nitpicky details I’m not thinking of, since they all take different amounts of current to yield the same output volume, I had to estimate consistent volume levels across all of the headphones. ↩︎