I’m not a “curator”
Curator’s Code is an attempt to codify and standardize “via” links and attribution from link blogs and aggregators with two new symbols:
- ᔥ means “via”
- ↬ means “hat tip”
It’s completely misguided.
First of all, readers aren’t going to learn what those symbols mean. The distinction between them is also unnecessary and will lead to more confusion: I’ve been running a hybrid articles-and-links blog here (↬DF) for a while, I wrote the function that added “via” links to billions of reblogged posts on Tumblr, and I didn’t even know the difference between “via” and “hat tip” until today.
But the inscrutability of these little symbols is irrelevant, because most writers aren’t going to use them.
The problems with online attribution aren’t due to a lack of syntax: they’re due to the economics and realities of online publishing.
Aggregation, over-quoting, and rewriting
Consider a typical post on The Verge, a widely respected tech blog:
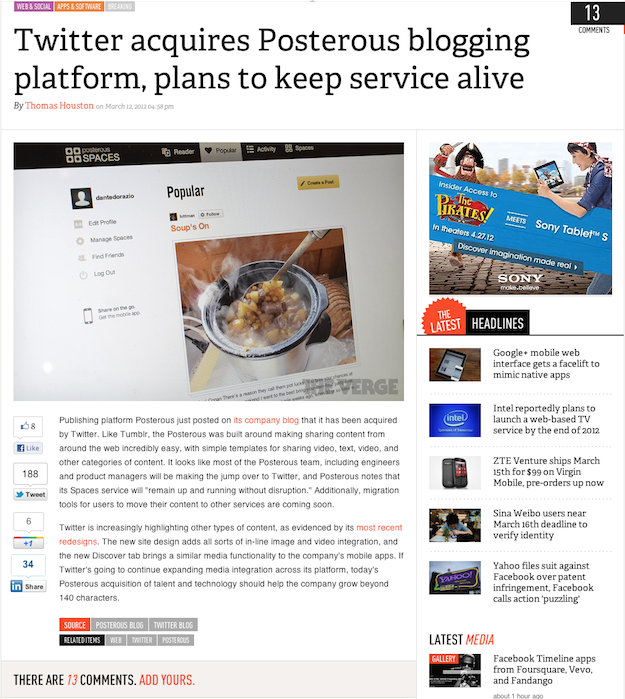
That post has three “via” links.
- Did you see them?
- Do you want to click on them?
I’m guessing you answered “No” to at least one of those. Two of the links are buried in the footer and look like tags. By the time anyone notices them, they’ve already read the entire post.
Many smart people have argued that purely inline source links solve this problem. But they don’t:

The source link is right there in the first sentence. But did you click on it? I didn’t, because I didn’t need to.
The problem isn’t whether readers can easily find the source link.
The real problem is that these posts replace the need for the source link.
Sites that do this can call this practice whatever they want. Often, it’s called aggregation, or simply reporting. There’s a continuum between 100% original reporting and zero value being added to the source content, but I don’t think I’m being unnecessarily inflammatory by labeling the posts on the far end of the continuum as rewriting.
When a post is rewritten, the rewriter knows that most of the audience won’t visit the original link. That’s the point. They don’t want to send anyone away from their site.
Rewriting sites (“aggregators”) will never adopt Curator’s Code in meaningful numbers because they don’t care. Whatever you think of what they do is irrelevant to them: they think it’s fine, their readers don’t care, and it seems to be legal.
Link blogs
Then there’s true link blogs:

Good link blogs are designed to send as many readers as possible to the source post by not only making it very easy to see the source link, but by not replacing the need to read it for most interested readers.
Link blogs don’t need a special symbol to denote their source or “via” link because it’s obvious. The link is the primary content.
Credit for discovery
The New York Times interviewed Maria Popova, the creator of Curator’s Code:
Ms. Popova, who spends hours a day scrounging the Web for remarkable artifacts, has noticed that many idiosyncratic discoveries suddenly become ubiquitous once unearthed. And the source of that little gem, or the credit for someone else who dug it up, often disappears when it is reposted.
“Discovery of information is a form of intellectual labor,” she said. “When we don’t honor discovery, we are robbing somebody’s time and labor. The Curator’s Code is an attempt to solve some of that.”
I don’t think this is very clear-cut. In fact, I completely disagree with Popova on the value of discovery.
The value of authorship is much more clear. But regardless of how much time it takes to find interesting links every day, I don’t think most intermediaries deserve credit for simply sharing a link to someone else’s work.
Reliably linking to great work is a good way to build an audience for your site. That’s your compensation.
But if another link-blogger posts a link they found from your link-blog, I don’t think they need to credit you. Discovering something doesn’t transfer any ownership to you. Therefore, I don’t think anyone needs to give you credit for showing them the way to something great, since it’s not yours. Some might as a courtesy, but it shouldn’t be considered an obligation.
Every link-blogger has their own standards for when to use a “via” link (or a “hat-tip” — again, I doubt most of us know the difference). I add a “via” if it’s convenient (if I can remember where I found the link) and I probably wouldn’t have seen it from any other sources.
If your standard is never to add a “via” to intermediate linkers, even when I am an intermediate linker, that’s fine with me, too.
And my syntax for adding a “via” link is… a link, often prepended by the word “via”. My readers understand.
Who gets credit?
One of the reasons I don’t add more “via” links is because it’s often difficult to trace the original “discoverer” of a link. The editor of a popular site similar to Instapaper’s Give Me Something To Read once complained to me via email that GMSTR occasionally “stole” links from his picks. But GMSTR’s editor had previously complained to me that the other editor would steal links from him. I told them both:
Finding the source of a particular article’s popularity at a particular time is never easy or obvious: sometimes it’s [the editor’s] own browsing, sometimes it’s mine, sometimes it’s a user-submitted link, […] sometimes it’s Jason Kottke, sometimes it’s John Gruber, sometimes it’s another prominent blogger, sometimes it’s Reddit, and most of the time, it’s just the target sites’ inherent popularity. (For instance, I don’t think anyone can really take credit for popularizing any recent articles on The New Yorker, The Atlantic, NY Mag, etc., since pretty much all of their articles are popular enough among smart web readers that they’ll be submitted to and noticed by all of our sites.)
I’d rather not engage any of these parties in any debates about who found something first. I don’t think the answer can be reasonably determined most of the time, and I also don’t think the answer matters to nearly anyone.
Can we agree not to argue between ourselves about who-found-it-first attribution, and just consider good story links as a free resource that we all pull from and that doesn’t belong to anyone?
And that’s how I feel about links in general: the source author creates something worth linking to, and the rest of us can link as we see fit, regardless of how we found it.
The proper place for ethics and codes is in ensuring that a reasonable number of people go to the source instead of just reading your rehash.
Codifying “via” links with confusing symbols is solving the wrong problem.